【新星计划】数据库 排名函数 初识 |
您所在的位置:网站首页 › mysql实现rank over › 【新星计划】数据库 排名函数 初识 |
【新星计划】数据库 排名函数 初识
|
数据库 排名函数 初识
查询排序初识排名函数row_number()rank()dense_rank()ntile()percent_rank()
开窗函数为聚合函数使用开窗函数
小结
查询排序
在日常工作中,我们对所有需要的数据都会进行一个排序操作,以获得我们最需要的数据。 排序指令 order 虽然已经很强大了,支持多个列同时排序,但是,在复杂场景下,还是有些捉襟见肘,比如,我要找到最新发布的第11篇到第20篇文章。 在古早时代,我们需要进行三次排序,第一次,找出最新的20篇文章,第二次,对这20篇倒序排列,找出最早的10篇,然后对这10篇进行时间排序并输出。 select * from ( select top 10 * from ( select top 20 * from articles order by pub_time desc ) a order by pub_time ) a order by pub_time descmysql 在这方面还是不错的,用 limit 可以指定,所以sqlserver 在 2005 版本的时候,就追加了排名函数支持。 select * from ( select *,row_number() over(order by pub_time desc) as sn from article ) a where sn between 11 and 20 order by sn在输出信息里追加了一个排名序号列,mysql 表示这都不是事,我们自己也可以变量完成这个操作,所以 mysql 的排名函数支持就严重滞后了,直到 mysql 8才开始支持,比oracle 都要晚不少了。 CSDN 文盲老顾的博客,https://blog.csdn.net/superwfei 初识排名函数在讲排名函数前,我们先用 leetcode 的第 180 题来模拟一下,在没有排名函数前,如果我们要实现这个查询,应该怎么做。 题目地址:https://leetcode.cn/problems/consecutive-numbers/ 编写一个 SQL 查询,查找所有至少连续出现三次的数字。 而这个题目中,id 是连续的,相对来说还是简单了,咱们弄个 id 不连续的来看看,但保证是按 id 递增来判断是否是连续数字 with t (id,num) as ( select 1,1 union all select 2,1 union all select 4,1 union all select 5,2 union all select 7,1 union all select 8,2 union all select 9,2 ) select * from t a left join t b on b.id=(select top 1 id from t where id>a.id and a.num=b.num order by id) left join t c on c.id=(select top 1 id from t where id>b.id and b.num=c.num order by id)
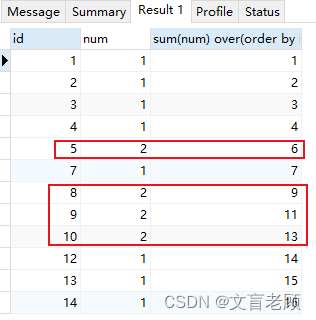
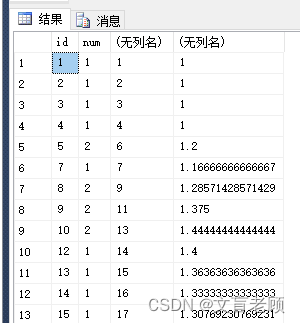
当然,leetcode 的这个题目还是比较简单的,只要求输出3个以上连续数字的数是几,没有要求输出连续位置,最大连续数量等等内容。 那么,我们在使用排名函数的话,会出现什么结果呢?老顾的文章《row_number 和 cte 使用实例:求不连续的分段结果》就是这样一种类似的需求下,写出来的一个解答方式。 还是用 leetcode 这个题目做个示例,不过数据我们扩充下,解答也扩充下。那么,先给出一个解答,再看排名函数。 with t (id,num) as ( select 1,1 union all select 2,1 union all select 3,1 union all select 4,1 union all select 5,2 union all select 7,1 union all select 8,2 union all select 9,2 union all select 10,2 union all select 12,1 union all select 13,1 union all select 14,1 union all select 15,1 ) select num 连续三次以上数字,count(0) 连续次数,min(id) 最小id,max(id) 最大id from ( select * ,row_number() over(order by id) rid ,row_number() over(partition by num order by id) nid from t ) a group by (rid - nid),num having(count(0) > 2) row_number()在这个题目的解答中,我们使用了 row_number,这就是一个排名函数,后边跟随的 over ,叫做开窗函数,语法百度一下大把的,就不细说了。 这里解释下刚才的指令的思路。 1、先按照 id 使用排名函数分配一个连续序号,保证在 id 或其他为依据的数据,在不连续的情况下也可正常使用。 2、二次使用排名函数,但是追加 partition 运算,即数据分区,使得每个相同的数字,各自独立再得到另外一个序号 3、两个序号相减。。。。数字相同,表示连续 4、按照相减结果分组统计,即可得到连续次数,连续开始位置,连续结束位置灯信息。 5、只需限定出现次数,可以方便的得到任意连续次数或及以上的结果,而不用每多一个数字就再追加一个join了 order 可以使用系统函数或变量,使其返回相同的值,则不会影响现有排序,比如 order by @@roucount,老顾以这个特性写过一篇文章《使用 row_number 获取实际返回行的行号》 rank()rank 和 row_number 差不多,不过 row_number 对于相同的值,给定的序号也是不同的,每个序号只会出现一次,而 rank 对于相同的值,给出的序号也是相同的。最常见的场景就是,如果出现并列第一,那么就没有第二名,直接第三名的样子。 dense_rank()这个和 rank 就非常非常相似了,不过这个分配的序号也是连续的,并列第一,并列第二,并列第三等等,不会跳过去了。 leetcode 185 就是一个典型用 dense_rank 解决起来非常简单的问题。 题目地址:https://leetcode.cn/problems/department-top-three-salaries/,有兴趣的小伙伴可以去实操一下。 ntile()这个函数,则略有差异了,需要指定一个参数了,比如 ntile(3),表示将数据分成三份,所影响的行各自分配到序号1、2、3,他会尽量平均分配的,同时,改分配也支持分区 partition。 percent_rank()最特殊的一个排名函数来了,这次返回的不是自然数了,而是一个浮点数。按名称也可以看出,这个是一个百分比结果 percent。而且,这个结果的值是从零到一,且包含零和一哦。 需要注意的一点是,由排名函数得到的值,在本层中无法参与到运算中,需要在外边套一层查询指令。但排名函数本身的运算是可以参与到 order 中的。 刚才已经讲过了,over 并不是排名函数,而是为了支持排名函数实现,所使用的另外一个类型的函数,这个才叫开窗函数,目前老顾仅仅知道 over 这一个。 而刚刚所用到的 order 排序也好,分区 partition 也好,都是属于开窗函数的,而不是排名函数。 再有,开窗函数中的排序仅影响排名序号,在无查询指令特意指定排序的情况下,会以最后一个 over 中的排序为依据作为最终排序结果,如果自行指定了 order 则忽略 over 中的 order。 为聚合函数使用开窗函数而开窗函数除了支持使用排名函数之外,其实,还支持聚合函数,比如 sum,这个用法老顾也是刚从问答里见过不久,暂时没有总结出特别好的用法和规律。这里给出一个示例,了解一下。老顾自己也还需要补课,这个就不展开来说了。 with t (id,num) as ( select 1,1 union all select 2,1 union all select 3,1 union all select 4,1 union all select 5,2 union all select 7,1 union all select 8,2 union all select 9,2 union all select 10,2 union all select 12,1 union all select 13,1 union all select 14,1 union all select 15,1 ) select * ,sum(num) over(order by id) from t
本文我们粗略的了解了一下排名函数、开窗函数以及附带提了一嘴的聚合函数。在实际工作中,灵活使用排名函数,会发现很多问题变得不再是问题了。 而且,mysql 由于实现排名函数和开窗函数的时机已经太晚了,所以,估计这些东西都是借鉴的 mssql ,用法,语法上基本完全一致,不存在跨数据库学习差异问题。 另外,对于排名函数的使用,解决了原有 group 分组时,部分字段不在分组依据时,无法列出的问题。当我们使用排名函数,以原来的分组作为分区时,就可以方便的得到原有需要的数据。。。嗯,是在没有聚合函数的情况下。有聚合运算时另说。
|
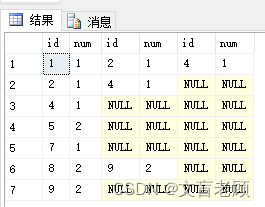 最后根据是否第三个表中有数据来判定是否连续。而如果连续数字较多,还需要进行排重。
最后根据是否第三个表中有数据来判定是否连续。而如果连续数字较多,还需要进行排重。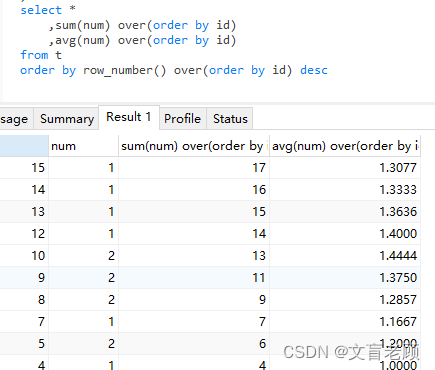

【本文地址】